Super Mario Bros. AI

The goal of this project was to use artificial intelligence techniques to create an agent to play the original NES Super Mario Bros. video game. The agent was trained with Deep Q-Learning, a reinforcement learning algorithm, along with a Convolutional Neural Network (CNN) to take in raw pixel data.
At the outset of this project, I had the following goals in mind for the agent:
Thus, this report will examine the methods used to accomplish the first goal, completing a single level from start to finish.
The first issue encountered was discovering that Retro, the emulator used for this project, is incompatible with PyTorch. Running the following lines in any order immediately resulted in the program terminating, without any warnings or errors:

Consequently, I used Keras, a high-level neural networks API, as the backend for the CNN. A second issue arose when attempting to speed up training by using Google Colaboratory, a Jupyter Notebook environment that allows the user to run their programs on a remote computer with an incredibly fast GPU. Unfortunately, Retro is not compatible with Google Colaboratory either, a truth discovered after several hours of attempting to import the correct libraries into the Notebook.
This section analyzes the techniques and methods that were used to accomplish the goal of completing a single level.
To begin, Retro, a wrapper for OpenAI Gym that can be interacted with via Python, was used as the emulator for this project due to its support of Super Mario Bros. and the ease of access of several necessary functions. Retro allows the user to open a game environment and choose actions within that environment each frame. To receive feedback from the environment, every frame Retro returns a reward, a boolean indicating if the game is finished or not, a 3D array of every pixel on the game’s screen, and a dictionary of further information. In the case of Super Mario Bros., this dictionary contains the number of coins earned, the time remaining, the number of lives, and the player score. Retro additionally allows the rendering of the environment to the screen, enabling watching the agent perform in real-time, and provides a way to record replays as compressed .bk2 files which can later be turned into .mp4 video files.
The emulator returns an array of size (224, 240, 3), representing the height, width, and RGB color value of each pixel on the game’s screen, respectively. This array is displayed below.

In order to reduce the load on the neural network and speed up training, the array is then processed using skimage, a Python image processing library1, as shown in the code below.

First, the image is converted to grayscale, removing the third channel from the array.

Next, the image is downscaled to roughly a quarter the resolution of the original image, a (65, 70) array.

Downscaling the resolution further will result in faster training, but the image may become too grainy for the CNN to make out edges and shapes. Conversely, downscaling the image less may make it easier for the network to make our shapes but will also make training much slower.
With the above downscaling, training on an 8-core Intel Xeon CPU @ 2.8GHz, each episode takes an average of 5 minutes to complete, with the saved weights for the network taking up 200 MB of space. If instead the image is only downscaled to half the original resolution, or an array of shape (112, 120), a single episode takes well over 30 minutes to complete, with the saved weights for the network taking up 4 GB of space. These results show the importance of image preprocessing to speed up training.
Once the images are preprocessed, they must then be stacked together using NumPy before being input to the neural network. This is done because the action chosen by the agent is dependent upon previous frames. For example, examine the following screenshot of Pong.

If you are either player, it is impossible to predict whether you should move the paddle up or down to intercept the ball, or indeed even if the ball is moving toward the left or right of the screen. However, if you are given several frames from the game, showing the ball in a slightly different position each time, it becomes apparent which direction the ball is heading. Stacking images is therefore important so the network has a sense of velocity, allowing it to interpret both the direction and speed of shapes on-screen and make a corresponding action8.

As Google’s DeepMind paper recommends2, I stack four frames together, making the array a shape of (56, 60, 4). Finally, Keras requires the array to be reshaped into (1, 56, 60, 4) before the network will accept the array, a fix borrowed from line 83 of Ben Lau’s program which creates a Deep Q-Network for playing Flappy Bird3. Since a new action is chosen every frame, the NumPy array of stacked frames is saved in memory rather than recreated each frame, allowing the oldest frame to be pushed off the array and the newest frame to be put in its place.
Before looking at the design of the Convolutional Neural Network, it is important to be aware of the input Retro requires for the action space in Super Mario Bros., as the network’s output was tailored to match this action space. The input to the emulator is an array of size nine where each value is either 1 or 0, representing the corresponding NES controller button pressed or not pressed. The network must therefore output something similar to this for Retro to use.
With this in mind, below is the code used to create the CNN model.
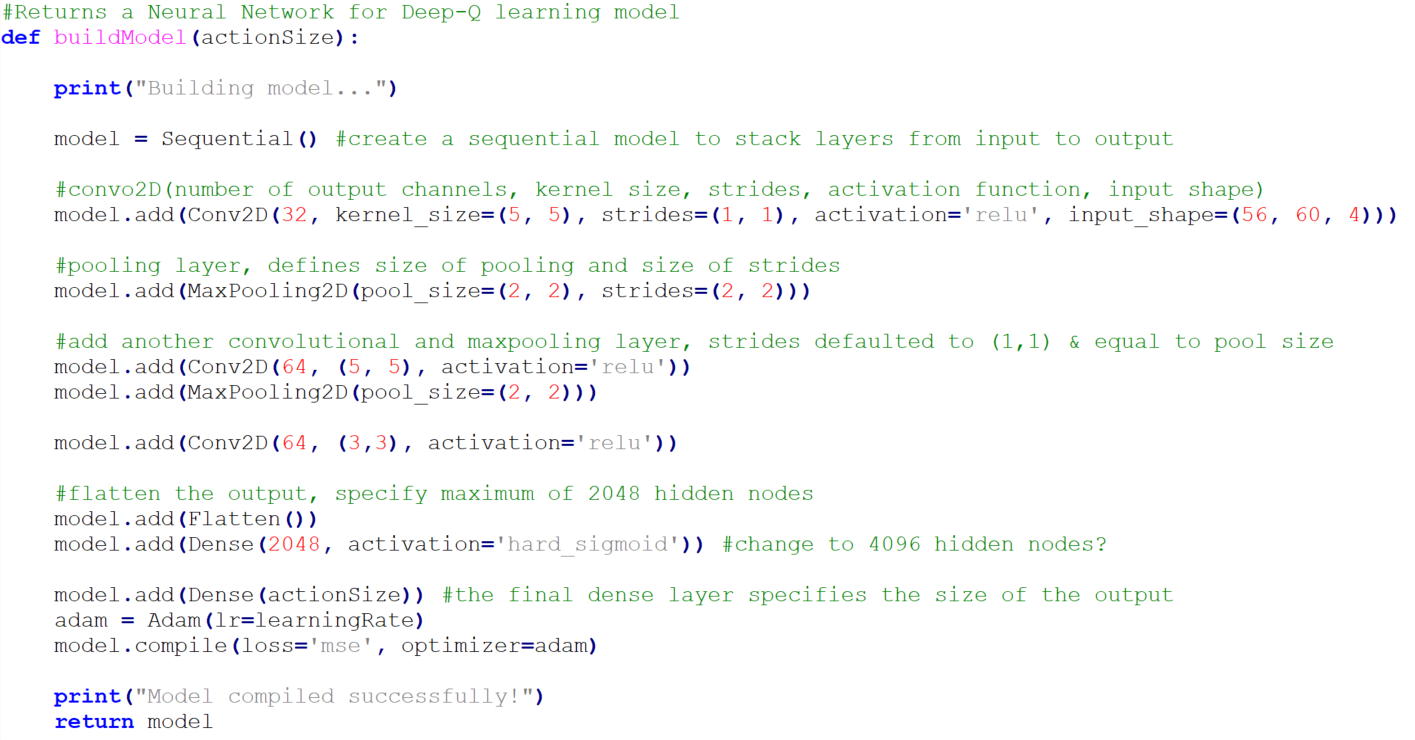
As can be seen, three 2D layers are created, two with pooling. The input shape to the first layer is set to the same shape as the array containing the processed and stacked frames, letting the network accept observations from the environment. The final activation is a hard sigmoid, restricting the output to floating-point numbers between 0 and 1, while the dense layer on the same line is of size 2048, specifying a maximum of 2048 hidden nodes. The final dense layer specifies the size of the network output, meaning how many numbers will be output in the range of 0 and 1, which is in this case nine, the size of our action space. Finally, the Adam optimizer is used with a learning rate of 1x10-4 and the model is compiled. This network is borrowed heavily from a GitHub repository created by Yilun Du in which he created a Deep Q-Network to play OpenAI Gym’s Space Invaders4.
With the CNN model created and set up to receive processed and stacked frames from the emulator, training can begin. The agent learns to make good actions in the environment by maximizing its reward and minimizing any penalties it receives, a form of training known as reinforcement learning6. The type of reinforcement learning used for this project is Q-Learning.
In Q-Learning, a table called a Q-Table is created, where each spot in the table represents the expected future reward for each action in each state. This value is referred to as the Q-value. The table is initialized to Q-values of 0 to indicate no reward or penalty for each state, and as the agent chooses actions the rewards and penalties are observed and are used to update the Q-Table, eventually filling it out as each action in each state is tried.
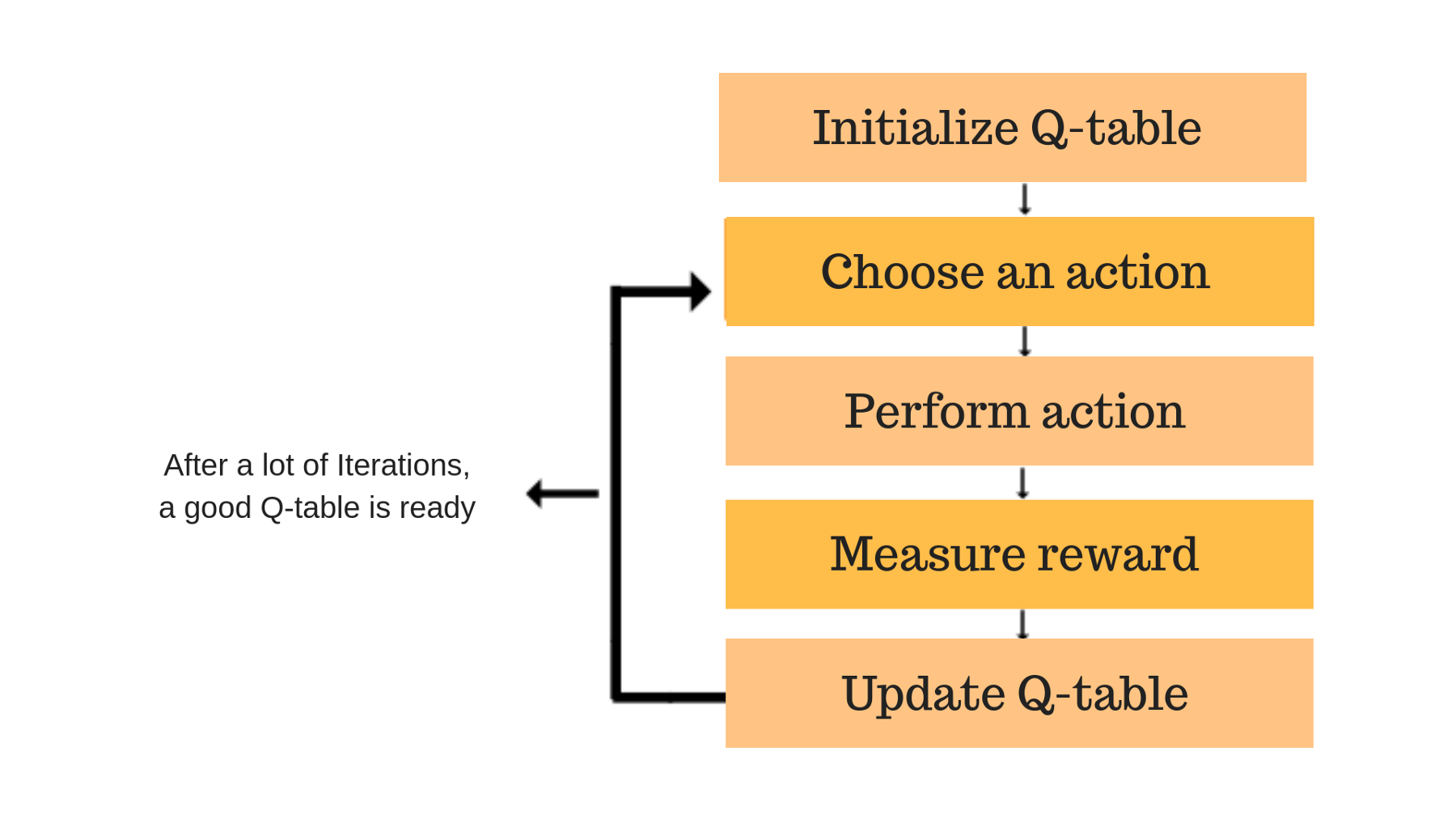
In order to fill out the Q-Table and explore the state space, an epsilon greedy strategy is used. This strategy features a value called epsilon that initially starts at 1, indicating that 100% of all actions chosen by the agent will be random. As the agent explores more of the environment, the epsilon value slowly drops, allowing the agent to choose its own actions according to the Q-Table and exploit the environment for rewards. This tradeoff is known as exploration vs. exploitation, where exploration is important to discover pathways for greater rewards in the state space and exploitation is important to capitalize on obtaining rewards already discovered. The epsilon value eventually drops to some minimum value, allowing the agent to fully exploit the state space for rewards7.
This strategy works fine for environments with a small number of states but in the case of video games like Super Mario Bros. each frame represents an entirely new state, making the size of the Q-Table massive. A variant of Q-Learning known as Deep Q-Learning solves this problem, where instead of using a table to estimate the Q-value a CNN is used. CNNs have the ability to generalize spatial relationships in images, drastically reducing the state space. As frames are fed in to the network for training, the network tunes a set of weights in the background, adjusting them to maximize expected reward8. The equivalent of updating the Q-Table based upon observed rewards then becomes tuning the weights in the network by fitting the model to states with known rewards. The training method with these concepts is shown below.

A random action, chosen by one of Retro’s functions, is chosen if the floating-point number generated is less than or equal to the current epsilon value. Otherwise, the agent is free to choose its own action, and the network is called on to estimate the Q-value. Since the output of the network is an array of nine floating-point numbers between 0 and 1, each number is rounded to 0 or 1 before being input to the emulator. Q-Learning also uses a gamma value to discount future rewards. A value of .95 was chosen based on Keon’s example9 of a Deep Q-Network for OpenAI Gym.
Fitting the model takes place during experience replay, where experiences are saved or remembered and then sampled in batches to train the neural network. This has two advantages; first, it prevents the network from forgetting previous experiences, and second, it reduces the correlation between experiences8.
To save experiences, a deque structure is created with a max size of 2000. During each frame a tuple of the 3D array, the network’s chosen action, the reward, the previous frame, and a boolean indicating whether the game is finished or not is appended to this data structure. If the deque is full, the oldest experience is replaced.

Every 500 in-game frames or 6 seconds the experience replay method is called. A batch of size 200 is chosen and the model is trained based on the expected and actual reward received from these states, as shown below.


Finally, each time the experience replay method is called, the epsilon value drops by being multiplied by the epsilon decay, a value less than 1. Smaller values for the epsilon decay will reduce the amount of time the agent has to explore and possibly result in a less optimal policy, while values closer to 1 will give the agent more time to explore, hopefully converging to a better policy but taking much more time to explore the state space until the agent is able to choose its own actions. I chose a value of 0.9995, a very slow decay that took around 20 hours of training to drop to the minimum epsilon value, .05.
The code for this experience replay is heavily borrowed from Keon’s GitHub repository on Deep Q-Learning9.
The agent is trained over several hundred episodes in a loop, resetting the environment at the end of each episode to the starting state. An episode is a single run of the game, usually terminated when the player has no lives remaining. At this point, Retro returns the status of the environment as “true”, indicating that the episode is finished. However, if the agent is allowed to play until Mario loses all his lives, it causes inconsistencies in evaluating the total reward gained for an episode.
Each time Mario dies his position is reset depending on how far he has made it in the level. If he has not passed the halfway point in the level, he will restart from the beginning, whereas if he is further than the halfway point, he will respawn at the halfway point. This means the total reward for an episode will be the cumulative progress Mario has made over each respawn, and this may have an unwanted effect on the agent, which is constantly trying to maximize its reward.
For example, say from the start of a level the agent can reach the halfway point, gaining a reward of 200. After this, the agent struggles to get more than 50 reward before dying and will respawn at the halfway point. Now consider two cases:
Case two results in a much higher reward than case one even though the agent makes it further through the level in case one. To avoid this problem the episode needs to be terminated once Mario has lost a life. Fortunately, this is possible due to the dictionary of extra information Retro returns each frame, which contains the number of Mario's lives. The game starts with two lives, but the episode cannot be terminated once Mario drops to one life, as Mario may gain an extra life through finding a 1Up shroom or getting 100 coins. While this is unlikely, it can be accounted for easily by creating a lives variable initialized to the number two. If Mario ever gains an extra life, the lives variable is incremented, but if the number of Mario’s lives are ever less than the variable, the agent has died and the episode can be terminated, as shown in the code below.


After extensive testing, it became apparent that training took a very long time and the agent still did not match up to expectations. This section describes two crucial changes made to the code. The original implementation of the project is in the file originalProject.py while the current and best version of the project with the changes described below are in a different file, project.py (see downloads). They were separated due to how significantly the methods in this section changed the code.
As mentioned in the Image Preprocessing section, each episode took an average of 5 minutes to complete. While this may not seem unreasonable, training the agent for 100 episodes takes over 8 hours. The agent was also very indecisive, even as the epsilon value dropped. This was because the agent was choosing several actions every second rather than sticking to a chosen action. To find out specifically how many actions per second it was choosing, it was possible to create a simple program where each time step the console printed the in-game time as well as the current frame number.

Looking at the time of 399 in the screenshot, there are 20 frames that pass for each in-game second. However, in-game time is not the same as real time, as the clock counts down much faster than a real second. By using a stopwatch, it can be determined that for every 50 in-game seconds that pass, 20 real seconds pass, meaning each in-game second is 20/50 or 0.4 of a second. Thus, if 20 frames pass during an in-game second, 20 frames/0.4 seconds gives 50 frames per second. This means the agent is choosing 50 actions within a single second, which is both unnecessary and computationally intensive.
Once again following Google’s DeepMind paper2, it makes sense to choose an action every fourth frame rather than every frame, skipping three frames and reducing the number of actions chosen per second to 12.5. Over the course of the skipped frames, the most recently chosen action is used, meaning if the agent chooses to jump the agent will be holding the jump button for four frames until a new action is chosen. This quickens training to where it now takes an average of 2.5 minutes to complete each episode, as the network only chooses actions a fourth as often as it did previously. The agent gains the additional benefit of becoming less decisive, performing each action longer than before.
This simplifies the process of stacking the frames together to input to the CNN, as the NumPy array of stacked frames no longer needs to be saved in memory to push the oldest frame out of the array and the newest frame into it but only needs to be created once every four frames and forgotten. The code below reflects these changes.

What is saved to the deque must also be changed, as now the reward will be the cumulative reward over four frames and the state and previous state saved will consist of four stacked frames each rather than a single frame as they were before.
Another change that drastically improved the agent was restricting the possible actions the agent could choose. The action space is an array of nine numbers, each one or zero to indicate the button pressed or not pressed. This comes out to 29 unique actions, or 512. Obviously, there are not that many actions to perform in Super Mario Bros., and the only concern is the agent’s ability to complete a single level. Moving to the left will not help the agent achieve this. Thus, we can remove it from our action space, constraining the agent’s available actions to just sprinting, moving to the right, and jumping. The number of unique actions drops from 512 to 4, with the agent choosing between moving to the right, moving to the right and jumping, moving to the right while sprinting, and moving to the right while jumping and sprinting.
To implement this change, the final dense layer of the network is changed to four to output an array of four numbers, each a float between 0 and 1.
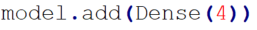
The highest value in the array the network outputs indicates the action that should be chosen. For example, given the array [0.65, 0.21, 0.73, 0.32], the highest value is 0.73, so the third action, moving to the right and sprinting, is chosen. The method below shows the lookup table for these actions along with the changes to the train method, which must now call the lookup table method after receiving the array from the network.


In order to create the lookup table, a test program called actions.py was created to determine how each array index corresponds to each action in-game.
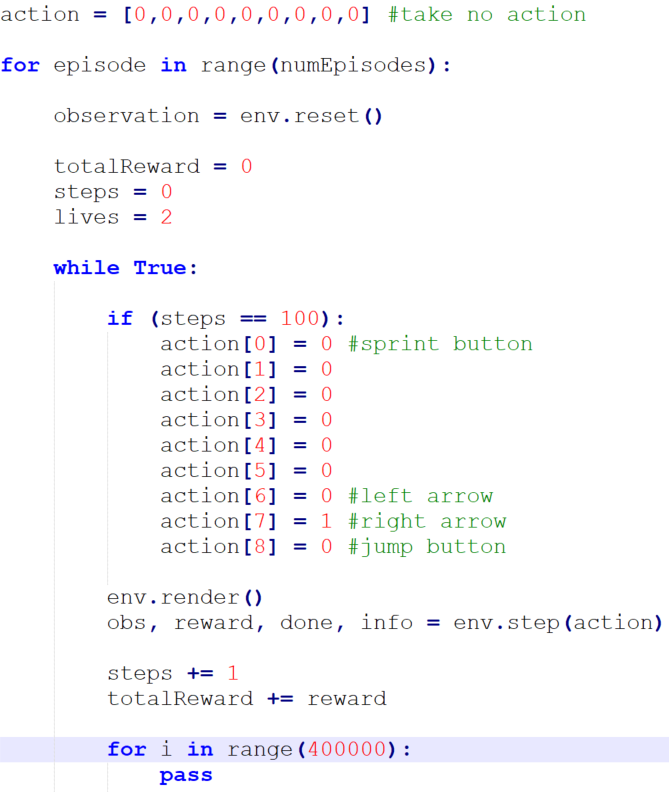
Mario is fed an empty action array for 100 frames, forcing him to stand still until the custom array is given to him, at which point he performs the action. Mario must initially stand still because some actions, such as jumping, are only performed once, after which holding the button has no effect. It takes a few seconds for the emulator to render on-screen and the user to maximize the window to observe these actions. A busy loop for 400,000 steps slows the emulator down enough to watch the agent perform close to real-time, avoiding the trouble of saving and converting replay files to watch the results. As can be seen, four of the actions were determined. The other five appeared to have no effect on Mario, a few of which can be explained by the up arrow having no purpose in Super Mario Bros. and the start and select buttons being disabled in Retro.
As mentioned previously, Retro provides a way to save episodes as compressed .bk2 files which can be turned into .mp4 files. Unfortunately, the function is fairly unintelligent, not providing a way to only save specific runs or distinguish the .bk2 files once they are saved. Training an agent for several hundred episodes results in a folder containing several hundred .bk2 files, all identical.
To solve this problem, two variables were created, one to track the total reward for an episode, totalReward, and one to track the largest total reward seen across every episode, maximumTotalReward. At the end of an episode, if the total reward is not larger than the maximum total reward, the .bk2 file saved by the function should be deleted since the agent did not perform better than the best previous episode. Otherwise, the replay should be saved and maximumTotalReward should be updated to the value of totalReward, as the last replay is the best seen. This forces only the best replays to be saved, and the best replay overall can easily be found as it is always the .bk2 file most recently saved. The code below shows this concept implemented.
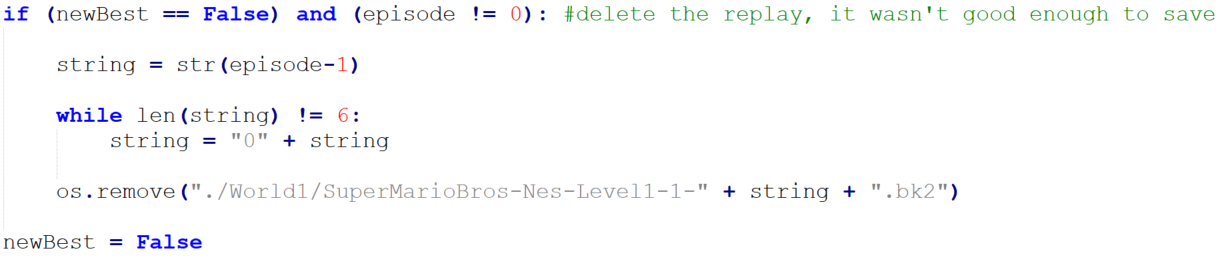

Retro records all .bk2 files in the following format: “SuperMarioBros-Nes-Level1-1-000000.bk2”, where “Level1-1” changes according to the starting stage (i.e., starting from world 2 would change the replay file to “Level2-1”). The six 0’s indicate the episode number, with the first episode saving as “000000”, the second episode saving as “000001”, and so on.
To delete saved replays, the Python function os.remove() is called, which takes a string. This string must be updated after each episode, incrementing by one like an integer to delete the proper .bk2 file. The string is made by first casting an integer representing the number of episodes minus 1 to a string. Episode 1 would make the string “0” while episode 56 would make the string “55”. A number of zeroes are then appended to the beginning of the string until the total string length is a size of six. In the examples, the strings would become “000000” and “000056”. This can finally be concatenated with the rest of the file name, which does not change between episodes.
This section will briefly explain a couple of techniques that appeared to have no effect on the quality of the trained agent, and so were not used in the final implementation.
The first is terminating the episode after a set number of frames pass with no reward. The idea is that if the agent is making no progress, there is little point to letting the episode play out, a concept borrowed from several websites on reinforcement learning in OpenAI Gym. However, this appeared to have no effect. Afterall, trying out actions that lead to no reward should still tune the weights in the network accordingly. This concept is used and can be seen in the original project file, originalProject.py, where if 1000 frames or 30 in-game seconds pass without a reward, the episode is terminated.
The second technique is implementing a heuristic to change the rewards. A penalty is given if the agent loses a life and a reward is given if the agent is moving to the right or jumping. The reward the emulator naturally gives for shifting the screen to the right is multiplied greatly to make it worth more than the reward for moving to the right or jumping, preventing the agent from “farming” points by walking infinitely against a pipe or other obstacle.

Despite this change to the reward, the agent did not die any less frequently or prioritize jumping or moving to the right more than other actions, so this was not used in either implementation of the project.
One less obvious issue that caused problems with training is the system for granting rewards. The emulator grants a reward to the agent as the screen shifts to the right, not necessarily as Mario moves to the right, although these two usually coincide. Sometimes these rewards are improperly granted. Here are two cases.
In the below clip, the agent comes up to a pipe and gets stuck. Notice that throughout the clip, the agent never manages to get over the pipe, making no net progress once it reaches the base of it. However, a reward is given to the agent. By constantly jump at the base of the pipe while attempting to move to the right, the screen shifts to the right. The screen also slightly shifts when Mario walks to the far left of the screen and then walks back to the right. This can incorrectly lead the agent to believe that jumping at the base of obstacles or moving to the left and then the right is a good policy to pursue, since it gained a reward by doing this. However, the agent does not make further progress in completing the level.
A partial solution to this problem is restricting the agent’s possible actions, as discussed previously. If the goal is to have the agent complete a level, it is understood that moving to left will not help the agent achieve this. Thus, we can remove it from our action space, constraining the agent’s available actions to just sprinting, moving to the right, and jumping. This prevents the agent from moving to the left and then back to the right to gain a reward. Unfortunately, this still leaves a second problem: delayed rewards.
In this second clip, the agent struggles for over thirty seconds to jump over a pipe. In this case, the agent’s actions are constrained, preventing it from moving to the left. The agent eventually reaches the top of the pipe and gains a reward as the frame moves to the right. However, the agent does not learn from this experience as it might seem. Since the reward is only given once the frame is moving to the right of the screen, the emulator grants the reward once Mario is standing on top of the pipe and making progress to the right, not when the agent is holding the jump key to get Mario to the top of the pipe.
This problem is worth mentioning but will in fact resolve itself. The agent will, given enough time, learn that holding the jump button to get over the pipe is the way to increase its reward, even if the reward is not immediately granted to the agent for holding the jump button. This is proven in the clip below, showing how the agent has learned to quickly jump over pipes it encounters by holding the jump button.
Let’s look at how the agent performed. This clip is the agent’s first successful run on World 1-1. Pay attention to when Mario jumps; it is not purely random. The agent prioritizes jumping when it encounters goombas and floating blocks and holds the jump key for an extended duration to gain extra height when encountering pipes and gaps.
This is the 64th attempt during the training of this agent. While the agent cannot consistently perform this well, it does on average perform much better than just taking random actions. The epsilon value for this episode is around .7, allowing the agent to choose 30% of the actions. While 70% seems like a high randomness value, the randomness is important in choosing actions that the agent may not correctly select.
As you can see, the agent quickly dies as soon as it passes to the second stage, as it had no training in that environment. Had successive runs begun from World 1-2, the agent would have performed much better. Unfortunately, Retro only allows environments in Super Mario Bros. to begin from the first stage of worlds 1 through 4, preventing the agent from starting on individual stages within each world or any stage in worlds 5 through 8. Had this been possible, it would have been a great experiment to train an agent on World 2-2, a water world, in which Mario must repeatedly press the jump button to stay afloat.
Let’s watch the agent try another, more difficult, stage, World 3-1. Note that this video has been edited, as a section where Mario struggles for 32 seconds to overcome the second pipe has been clipped out.
This is the agent’s 208th attempt on this world. While it may have been lucky in obtaining the invincibility star, it nearly completes the level (the finish was just after the enemy it died to), proving that with enough time it may have been able to solve it.
Another point to showcase is the agent’s ability to find secrets. While this is still possible in the later implementation of the program, where the agent’s actions are constrained to moving to the right (as proven by the agent finding the invincibility star and vine in the previous clip), it was more likely to occur when the agent had freedom to explore the entire environment. The following clip shows a couple of secrets the agent found while it still had free-reign over its actions.
Had the program been tailored toward the agent collecting as many coins as possible or obtaining as many points as possible, these discoveries would have been very beneficial to the agent.
In watching several replays of the agent, there were moments when Mario performed a seemingly impossible action, one that would logically lead to death but did not. These can tentatively be labeled as exploits even though they are not particularly beneficial towards achieving any goal in the game, with the exception of the agent discovering it can pass through piranha plants by sprinting, a well-known exploit5 utilized by speed-runners. Here are a few such moments.
Of course, not all of the agent's gameplay was recorded and watched, meaning there were likely several more secrets and “exploits” that the agent discovered, but this is enough to prove the point that the agent discovered several interesting things as it explored the environment in an attempt to achieve its goal.
If you would like to see additional clips of the agent playing or see how the agent performed on worlds 2 and 4, follow this GitHub link.
If you would like to run my program to either train an agent for yourself or watch the agent play with the weights already trained, follow the instructions to install Retro for your machine here.
Retro supports many environments but does not host the ROMs for those environments, so you will need to find a ROM for the game. After, run the import instructions as outlined by Retro.
Next, you must have Keras installed on your system. Keras additionally requires TensforFlow, Theano, or CNTK for backend; I used Tensorflow, which Keras recommends. Keras is not compatible with Python 3.7; you must use Python 2.7-3.6.
The program is currently set up to allow the user to run World 1-1 with loading the weights, with the exception of line 23 (see below). Make sure world1-1Weights.h5 is in the same folder as the program, project.py, and that you have an additional empty folder in this directory labeled “World1” to save the .bk2 replay files.
To convert .bk2 files into .mp4 files, run the following command from the program directory, where World1 is the folder the replays are saved:
python -m retro.scripts.playback_movie ./World1/SuperMarioBros-Nes-Level1-1-000000.bk2
Important lines in project.py to note:
project.py - the final implemenation of the project
originalProject.py - the project without frame skipping or a restricted action space
actions.py - the test program for mapping array indices to actions
Weights - the trained neural network weights for worlds 1-4
Website source code - the repository containing this website's source code
Utilizing Deep Q-Learning, a CNN, and the above methods, an intelligent agent was able to be successfully trained for the purpose of completing a single level from start to finish in Super Mario Bros.
Future works will explore accomplishing the goals outlined in the Goals section, particularly training an agent to play two different levels simultaneously with one input for the controls.
Name: Kendall Haworth
Email: kehaworth@cpp.edu